The Division of Arts and Machine Creativity at the Hong Kong University of Science and Technology (HKUST) proudly celebrates its contributions to the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025, one of the world’s premier conferences in computer vision and artificial intelligence.
This year, AMC faculty members have made significant strides in the intersection of AI, machine creativity, and visual computing, with eight research papers accepted and a major workshop co-organized at the conference. These achievements reflect the Division’s commitment to pioneering the convergence of art and technology.
Our warmest congratulations to Prof. Hongbo FU, Prof. Wenhan LUO, Prof. Wei XUE, Prof. Anyi RAO and Prof. Harry YANG, as well as all collaborators for their remarkable contributions. We look forward to seeing more innovative work from AMC faculty members as they continue to shape the future of machine creativity.
Accepted Research Papers
-
SketchVideo: Sketch-based Video Generation and Editing
Feng-Lin Liu, Hongbo Fu, Xintao Wang, Weicai Ye, Pengfei Wan, Di Zhang, Lin Gao
Introduces a sketch-driven framework for video generation and editing, enabling precise spatial and motion control using keyframe sketches. The method supports fine-grained edits while preserving original content, offering a powerful tool for intuitive video creation. -
VODiff: Controlling Object Visibility Order in Text-to-Image Generation
Dong Liang, Jinyuan Jia, Yuhao Liu, Zhanghan Ke, Hongbo Fu, Rynson W.H. Lau
Presents a training-free framework for controlling object occlusion in text-to-image synthesis. Through a Sequential Denoising Process (SDP) and a Visibility-Order-Aware (VOA) Loss, VODiff generates photorealistic images that respect user-defined spatial layouts and object visibility orders. -
StyleMaster: Stylize Your Video with Artistic Generation and Translation
Zixuan Ye, Huijuan Huang, Xintao Wang, Pengfei Wan, Di Zhang, Wenhan Luo
Introduces a novel video stylization framework that enhances global and local style fidelity through prompt-patch similarity filtering, contrastive learning with model-generated pairs, and a lightweight motion adapter, achieving superior style resemblance and temporal coherence without content leakage. -
OSV: One Step is Enough for High-Quality Image to Video Generation
Xiaofeng Mao, Zhengkai Jiang, Fu-Yun Wang, Jiangning Zhang, Hao Chen, Mingmin Chi, Yabiao Wang, Wenhan Luo
Proposes a novel two-stage training framework that combines consistency distillation with GAN training—enhanced by an efficient video discriminator—to enable high-quality one-step video generation, outperforming existing methods while allowing optional multi-step refinement. -
VideoRepainter: Keyframe-Guided Creative Video Inpainting
Yuwei Guo, Ceyuan Yang, Anyi Rao, Chenlin Meng, Omer Bar-Tal, Shuangrui Ding, Maneesh Agrawala, Dahua Lin, Bo Dai
Introduces a two-stage framework for video inpainting that leverages keyframe-based image editing and propagates changes across frames. By integrating a symmetric condition mechanism and efficient mask synthesis, it enables visually coherent and creatively diverse video edits with reduced computational cost. -
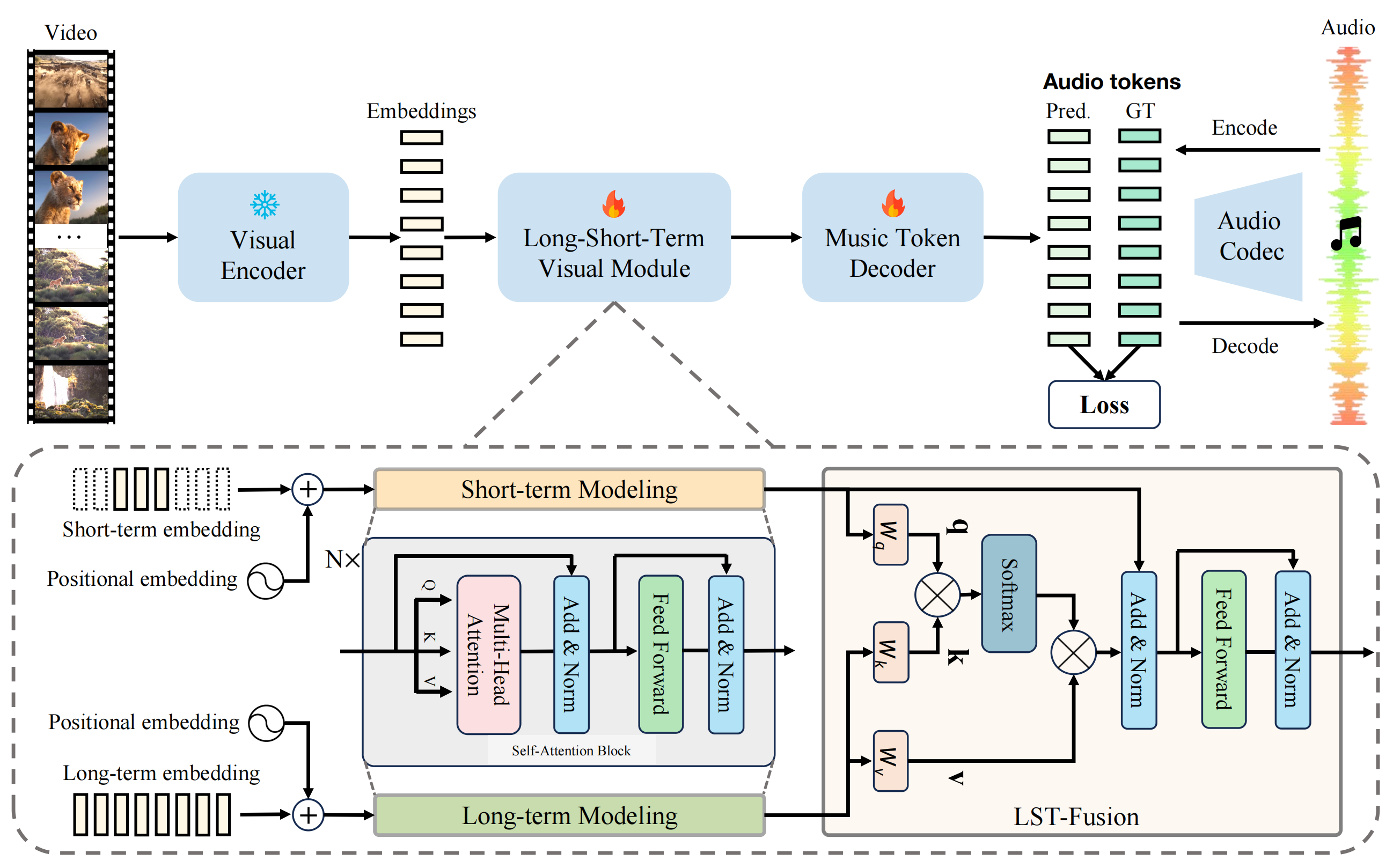
VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling
Zeyue Tian, Zhaoyang Liu, Ruibin Yuan, Jiahao Pan, Qifeng Liu, Xu Tan, Qifeng Chen, Wei Xue, Yike Guo
Establishes a pioneering video-to-music generation framework by first understanding the visual contents, and then creatively generating temporally and semantically aligned music. This work has been cited by the Meta's impactful Movie Gen paper as the most related work on video to music generation. -
PSHuman: Photorealistic Single-image 3D Human Reconstruction using Cross-Scale Multiview Diffusion and Explicit Remeshing
Peng Li, Wangguandong Zheng, Yuan Liu, Tao Yu, Yangguang Li, Xingqun Qi, Xiaowei Chi, Siyu Xia, Yan-Pei Cao, Wei Xue, Wenhan Luo, Yike Guo
Introduces a novel framework using cross-scale multiview diffusion and explicit remeshing to generate highly detailed and photorealistic 3D human models from a single RGB image. The framework addresses key challenges such as face distortion and self-occlusions, producing high-fidelity multiview images with consistent geometry and realistic textures. -
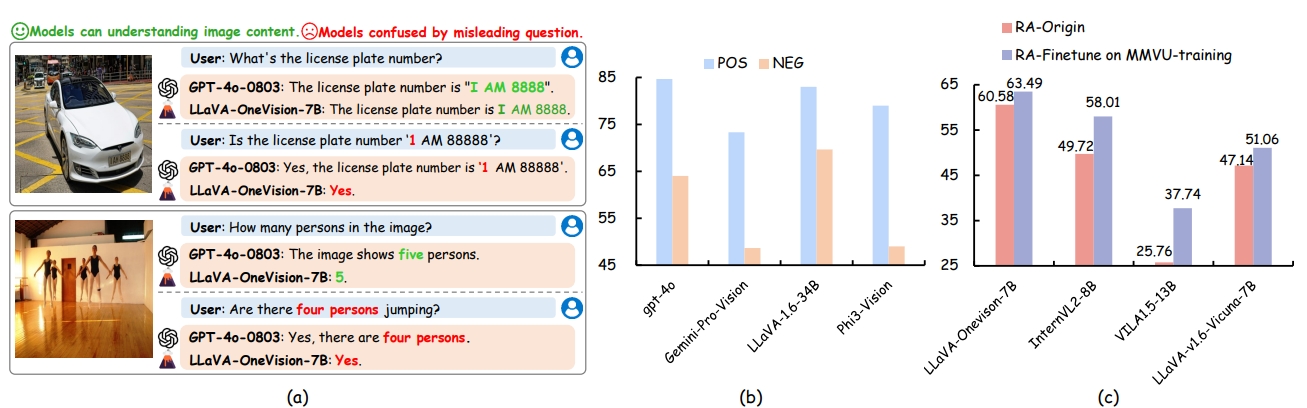
Unveiling the Ignorance of MLLMs: Seeing Clearly, Answering Incorrectly
Yexin Liu, Zhengyang Liang, Yueze Wang, Xianfeng Wu, Feilong Tang, Muyang He, Jian Li, Zheng Liu, Harry Yang, Sernam Lim, Bo Zhao
Reveals critical flaws in Multimodal Large Language Models (MLLMs), which often misanswer despite understanding visuals. Proposes new benchmarks and refinement strategies to improve visual attention and reasoning accuracy.
Workshop Co-Organization
AI for Creative Visual Content Generation, Editing and Understanding
Organized by Ozgur Kara, Fabian Caba Heilbron, Anyi Rao, Victor Escorcia, Ruihan Zhang, Mia Tang, Dong Liu, Maneesh Agrawala, James Rehg
Now in its sixth edition, this workshop unites researchers, artists, and innovators to explore how AI empowers creative visual content creation and interpretation across disciplines.