The Division of Arts and Machine Creativity (AMC) at the Hong Kong University of Science and Technology (HKUST) is proud to announce its impactful presence at the upcoming IEEE International Conference on Computer Vision (ICCV) 2025, a globally renowned forum for breakthroughs in computer vision and artificial intelligence, scheduled to take place in Honolulu, Hawaii from 19–23 October, 2025.
This year, AMC faculty members continue to push the boundaries of AI, machine creativity and visual computing, with seven high-calibre research papers accepted at the conference. These accomplishments underscore the Division’s dedication to advancing interdisciplinary innovation at the nexus of art and technology.
Our warmest congratulations to Prof. Hongbo FU, Prof. Wenhan LUO, Prof. Wei XUE and Prof. Harry YANG, along with their collaborators, for their outstanding contributions. Their work not only exemplifies academic excellence but also reinforces AMC’s leadership in shaping the future of machine creativity.
Accepted Research Papers
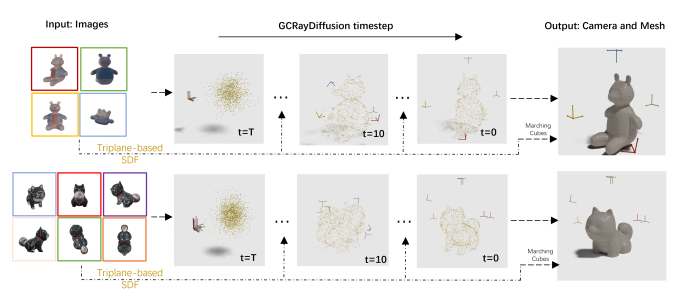
- GCRayDiffusion: Pose-Free Surface Reconstruction via Geometric Consistent Ray Diffusion
Li-Heng Chen, Zi-Xin Zou, Chang Liu, Tianjiao Jing, Yan-Pei Cao, Shi-Sheng Huang, Hongbo Fu, Hua Huang
Proposes a pose-free surface reconstruction method that combines triplane-based SDF learning with ray-based diffusion for accurate camera pose estimation, achieving superior reconstruction quality even in sparse-view scenarios. - MaterialMVP: Illumination-Invariant Material Generation via Multi-view PBR Diffusion
Zebin He, Mingxin Yang, Shuhui Yang, Yixuan Tang, Tao Wang, Kaihao Zhang, Guanying Chen, Yuhong Liu, Jie Jiang, Chunchao Guo, Wenhan Luo
Solves PBR texture synthesis through reference-guided attention and dual-channel generation, delivering lighting-consistent albedo/metallic-roughness textures for scalable 3D asset creation—outperforming existing methods in multi-view stability and realism. - MOERL: When Mixture-of-Experts Meet Reinforcement Learning for Adverse Weather Image Restoration
Tao Wang, Peiwen Xia, Bo Li, Peng-Tao Jiang, Zhe Kong, Kaihao Zhang, Tong Lu, Wenhan Luo
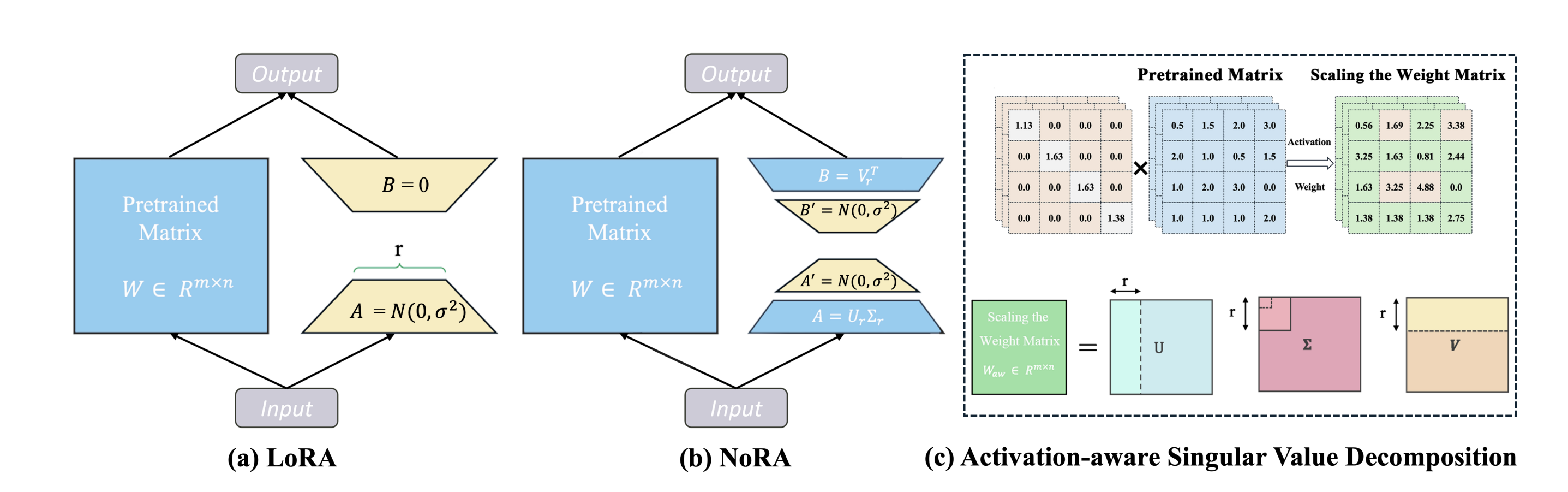
Introduces a human-like progressive restoration framework using RL-optimized Mixture-of-Experts (channel/spatial modulation) to dynamically adapt to rain, snow, and haze degradations, outperforming fixed-architecture alternatives. - Efficient Fine-Tuning of Large Models via Nested Low-Rank Adaptation
Lujun Li, Cheng Lin, Dezhi Li, You-Liang Huang, Wei Li, Tianyu Wu, Jie Zou, Wei Xue, Sirui Han, Yike Guo
Presents NoRA, a nested parameter-efficient LoRA structure that revolutionizes the initialization and fine-tuning of projection matrices. The NoRA's innovative approach involves freezing outer layer LoRA weights and employing a serial inner layer design, enabling precise task-specific adaptations while maintaining compact training parameters. - AIRA: Activation-Informed Low-Rank Adaptation for Large Models
Lujun Li, Dezhi Li, Cheng Lin, Wei Li, Wei Xue, Sirui Han, Yike Guo
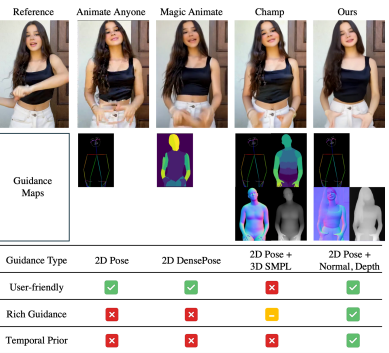
Presents Activation-Informed Low-Rank Adaptation (AIRA), a novel approach that integrates activation information into initialization, training, and rank assignment to enhance the performance of Low-Rank Adaptation (LoRA) of large models. Specifically, AIRA introduces a cascaded activation-informed paradigm which enables faster convergence and fewer fine-tuned parameters, achieving superior performance-efficiency trade-offs in vision-language instruction tuning, few-shot learning, and image generation. - DreamDance: Animating Human Images by Enriching 3D Geometry Cues from 2D Poses
Yatian Pang, Bin Zhu, Bin Lin, Mingzhe Zheng, Francis E. H. Tay, Ser-Nam Lim, Harry Yang, Li Yuan
Introduces a novel diffusion-based method to animate human images using only 2D skeleton poses, enriching them with 3D geometry cues for high-quality results. It leverages a new TikTok-Dance5K dataset, Mutually Aligned Geometry Diffusion Model and a multi-level guidance system to achieve state-of-the-art animation performance. - Model Reveals What to Cache: Profiling-Based Feature Reuse for Video Diffusion Models
Xuran Ma, Yexin Liu, Yaofu Liu, Xianfeng Wu, Mingzhe Zheng, Zihao Wang, Ser-Nam Lim, Harry Yang
Introduces an adaptive caching strategy for video diffusion models by distinguishing foreground and background-focused blocks, optimizing computational efficiency. This selective caching substantially reduces computational overhead while preserving visual fidelity, achieving up to 2× acceleration without compromising visual quality.